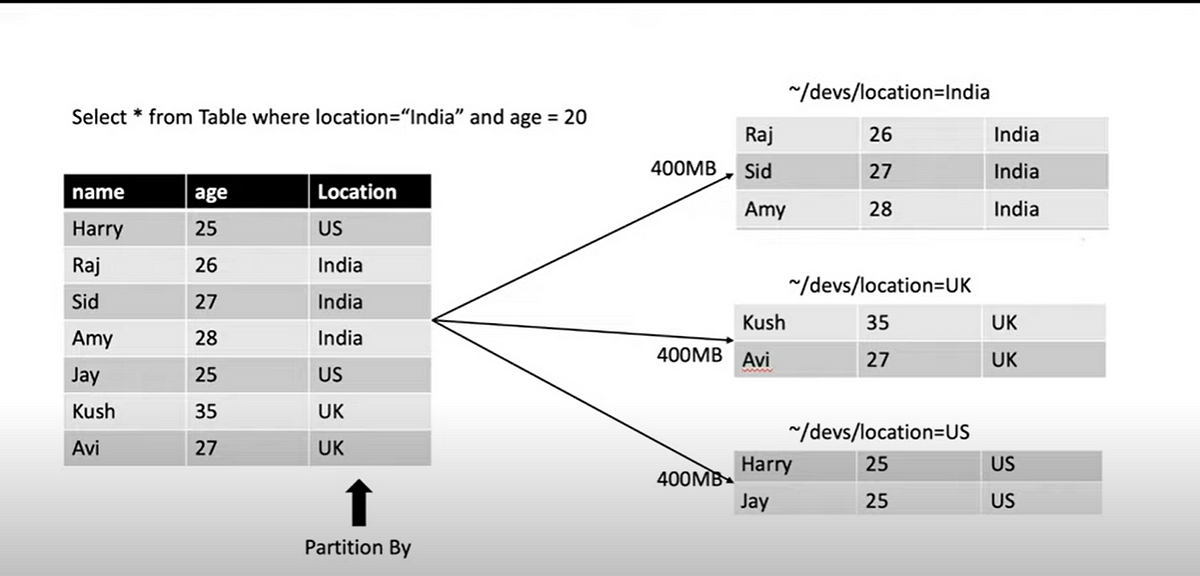
Partitioning And Bucketing In Spark With Examples . We've got two tables and we do one simple inner join by one column: partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. Partitions are the basic units of. Don't collect data on driver. Partitioning divides the data into smaller parts for improved processing, while bucketing groups. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time of creating a hive table. These techniques provide data management solutions that enhance query speed and resource. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. Let's start with the problem. both partitioning and bucketing are techniques used to organize data in a spark dataframe. apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain()
from medium.com
We've got two tables and we do one simple inner join by one column: apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. These techniques provide data management solutions that enhance query speed and resource. Partitions are the basic units of. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time of creating a hive table. Don't collect data on driver. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. both partitioning and bucketing are techniques used to organize data in a spark dataframe. Let's start with the problem. Partitioning divides the data into smaller parts for improved processing, while bucketing groups.
Partitioning vs Bucketing in Spark and Hive by Shivani Panchiwala
Partitioning And Bucketing In Spark With Examples partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. both partitioning and bucketing are techniques used to organize data in a spark dataframe. apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. Don't collect data on driver. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Partitions are the basic units of. We've got two tables and we do one simple inner join by one column: These techniques provide data management solutions that enhance query speed and resource. Partitioning divides the data into smaller parts for improved processing, while bucketing groups. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. Let's start with the problem. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time of creating a hive table.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Partitioning And Bucketing In Spark With Examples Don't collect data on driver. Partitioning divides the data into smaller parts for improved processing, while bucketing groups. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. both partitioning and bucketing are techniques used to organize data in a. Partitioning And Bucketing In Spark With Examples.
From www.youtube.com
Why should we partition the data in spark? YouTube Partitioning And Bucketing In Spark With Examples partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. Let's start with the problem. Partitions are the basic units of. We've got two tables and we do one simple inner join by one column: Don't collect data on driver. These techniques provide data management solutions that enhance query speed and resource.. Partitioning And Bucketing In Spark With Examples.
From www.youtube.com
Spark SQL Bucketing at Facebook Cheng Su (Facebook) YouTube Partitioning And Bucketing In Spark With Examples two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. both partitioning and bucketing are techniques used to organize data in a spark dataframe. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() . Partitioning And Bucketing In Spark With Examples.
From bigdatansql.com
Bucketing_With_Partitioning Big Data and SQL Partitioning And Bucketing In Spark With Examples both partitioning and bucketing are techniques used to organize data in a spark dataframe. We've got two tables and we do one simple inner join by one column: Partitions are the basic units of. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Don't collect data on driver. with partitions, hive divides(creates a directory) the table into smaller parts. Partitioning And Bucketing In Spark With Examples.
From kontext.tech
Spark Bucketing and Bucket Pruning Explained Partitioning And Bucketing In Spark With Examples Don't collect data on driver. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time of creating a hive table. We've got two tables and we do one simple inner join by one column: both. Partitioning And Bucketing In Spark With Examples.
From www.clairvoyant.ai
Bucketing in Spark Partitioning And Bucketing In Spark With Examples both partitioning and bucketing are techniques used to organize data in a spark dataframe. Partitioning divides the data into smaller parts for improved processing, while bucketing groups. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. We've got two tables and we do one simple inner join by one column: Don't collect data. Partitioning And Bucketing In Spark With Examples.
From jaceklaskowski.github.io
Join Optimization With Bucketing (Spark SQL) Partitioning And Bucketing In Spark With Examples partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. both partitioning and bucketing are techniques used to organize data in a spark dataframe. We've got two tables and we do one simple inner join by one column: apache spark’s bucketby() is a method of the dataframewriter class which is. Partitioning And Bucketing In Spark With Examples.
From towardsdata.dev
Partitions and Bucketing in Spark towards data Partitioning And Bucketing In Spark With Examples apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. Partitions are the basic units of. Let's start with the problem. These techniques provide data management solutions that enhance query speed and resource. Partitioning. Partitioning And Bucketing In Spark With Examples.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Partitioning And Bucketing In Spark With Examples partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. Don't collect data on driver. two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Partitions are the basic units of. We've got two tables and we do one. Partitioning And Bucketing In Spark With Examples.
From blog.det.life
Data Partitioning and Bucketing Examples and Best Practices by Partitioning And Bucketing In Spark With Examples We've got two tables and we do one simple inner join by one column: two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Partitions are the basic units of. partitioning in spark refers to the division of data into smaller, more manageable chunks known as. Partitioning And Bucketing In Spark With Examples.
From www.okera.com
Bucketing in Hive Hive Bucketing Example With Okera Okera Partitioning And Bucketing In Spark With Examples T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time. Partitioning And Bucketing In Spark With Examples.
From medium.com
Partitioning vs Bucketing in Spark and Hive by Shivani Panchiwala Partitioning And Bucketing In Spark With Examples Partitions are the basic units of. apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. both partitioning and bucketing are techniques used to organize data in a spark dataframe. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a. Partitioning And Bucketing In Spark With Examples.
From www.youtube.com
Bucketing in Hive with Example Hive Partitioning with Bucketing Partitioning And Bucketing In Spark With Examples apache spark’s bucketby() is a method of the dataframewriter class which is used to partition the data based on the. We've got two tables and we do one simple inner join by one column: two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Don't collect. Partitioning And Bucketing In Spark With Examples.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partitioning And Bucketing In Spark With Examples two core features that contribute to spark’s efficiency and performance are bucketing and partitioning. These techniques provide data management solutions that enhance query speed and resource. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the. Partitioning And Bucketing In Spark With Examples.
From medium.com
Apache Spark Bucketing and Partitioning. by Jay Nerd For Tech Medium Partitioning And Bucketing In Spark With Examples T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() We've got two tables and we do one simple inner join by one column: partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas. Partitioning And Bucketing In Spark With Examples.
From keypointt.com
Hive Bucketing in Apache Spark Tech Reading and Notes Partitioning And Bucketing In Spark With Examples with partitions, hive divides(creates a directory) the table into smaller parts for every distinct value of a column whereas with bucketing you can specify the number of buckets to create at the time of creating a hive table. Let's start with the problem. both partitioning and bucketing are techniques used to organize data in a spark dataframe. These. Partitioning And Bucketing In Spark With Examples.
From www.semanticscholar.org
Figure 1 from Partitioning and Bucketing Techniques to Speed up Query Partitioning And Bucketing In Spark With Examples partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. both partitioning and bucketing are techniques used to organize data in a spark dataframe. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Let's start with the problem. We've got two tables and we do one simple inner join by one column:. Partitioning And Bucketing In Spark With Examples.
From laptrinhx.com
Best Practices for Bucketing in Spark SQL LaptrinhX Partitioning And Bucketing In Spark With Examples We've got two tables and we do one simple inner join by one column: partitioning in spark refers to the division of data into smaller, more manageable chunks known as partitions. both partitioning and bucketing are techniques used to organize data in a spark dataframe. T1 = spark.table(unbucketed1) t2 = spark.table(unbucketed2) t1.join(t2, key).explain() Partitions are the basic units. Partitioning And Bucketing In Spark With Examples.